The Platform for
AI Security
SECURE YOUR AI. EVERYWHERE IT MATTERS.



















AI introduces a new array of security risks
We would know. As core members of the OWASP research team, we have unique insights into how AI is changing the cybersecurity landscape.
Introducing prompt Security
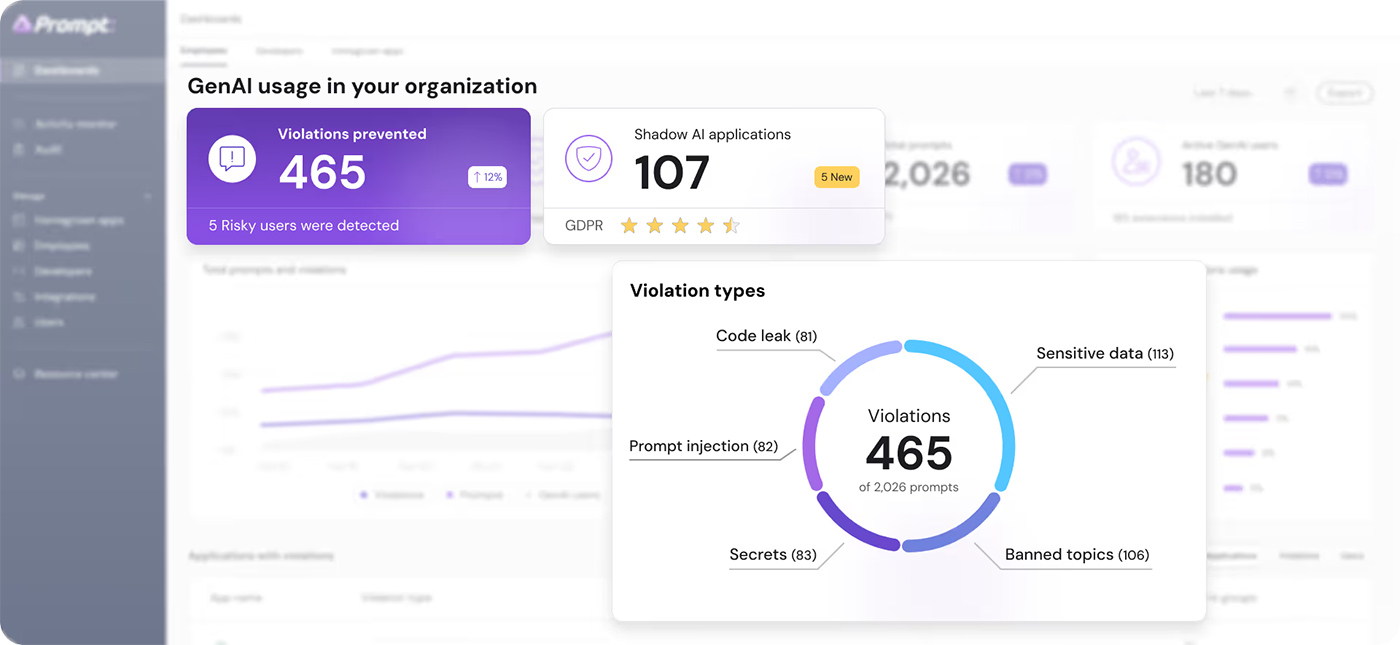
Prompt Security defends against AI risks at all levels
A complete solution for safeguarding AI at every touchpoint in the organization

Prompt for Employees
Enable your employees to adopt AI tools without worrying about Shadow AI, Data Privacy and Regulatory risks.

Prompt for Homegrown AI Apps
Unleash the power of AI in your homegrown applications without worrying about AI security risks.

Prompt for AI Code Assistants
Securely integrate AI into development lifecycles without exposing sensitive data and code.

Prompt for Agentic AI Security
Agentic AI, accelerated by MCP, can now execute tasks autonomously, demanding real-time, machine-level security for visibility, risk assessment, and enforcement beyond traditional analysis boundaries.













Enterprise-Grade AI Security
Fully LLM-Agnostic

Seamless integration into your existing AI and tech stack
Getting started with Prompt Security is fast and easy, regardless of how your tech stack looks like.

Cloud or self-hosted deployment
It's your choice. Prompt Security can be delivered as SaaS or on-premises based on your unique needs.

Trusted by Industry Leaders
%202.png)
Tamir Ronen
Global CISO at HiBob
%201.png)

Avihai Ben Yossef
CTO & co-founder at cymulate

.avif)
Dr. Danny Portman
Head of Generative AI, Zeta Global


Shawn Bower
Chief Information Security Officer at The New York Times


Richard Moore
CISO at 10x Banking


Dave Perry
Manager, Digital Workspace Operations at St. Joseph's Healthcare Hamilton


Sharon Schwartzman
CISO at Upstream
.png)
The Key Layer in AI Security: Browser and Endpoint Sensors

AI Risk Assessment Tool
Get instant access to detailed risk assessments powered by Prompt Security's specialized scoring methodology. Whether you're evaluating popular AI tools or assessing MCP servers, our platform provides transparent risk scores, parameter breakdowns, and certification status checks.
Time to see for yourself
See how organizations are securely enabling AI with
Prompt Security